16.4. 常见统计量:样本矩#
假定在样本 \(x_1,x_2,\cdots,x_n\) 中有 \(k\) 个不同的取值 \(a_1,a_2,\cdots,a_k\) 。每一个样本 \(x_i\) 来自于一个均值为 \(\mu\) 和方差为 \(\sigma^2\) 分布的随机变量。
数据 |
\(a_1\) |
\(a_2\) |
\(\cdots\) |
\(a_k\) |
频数 |
\(m_1\) |
\(m_2\) |
\(\cdots\) |
\(m_k\) |
频率 |
\(\frac{m_1}{n}\) |
\(\frac{m_2}{n}\) |
\(\cdots\) |
\(\frac{m_k}{n}\) |
Remark
\(\sum_{i=1}^{k} m_{i}=n ,\sum_{i=1}^{k} a_{i} m_{i}=\sum_{i=1}^{n} x_{i}\) 。
因为 \(F_n(x)\) 是一个某个随机变量的分布函数,假定该随机变量为 \(X\) ,所以,
Remark
我们通常记 \(\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_{i}\) ,而 \(s_{n}^2 = \frac{1}{n} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}\) 。
- 样本 \(k\) 阶中心距
设 \(x_1,x_2,\cdots,x_n\) 是样本, \(k\) 为正整数,则统计量
称为样本 \(k\) 阶原点矩;统计量
称为样本 \(k\) 阶中心矩。
Remark
样本一阶原点矩是样本均值;样本二阶中心矩是样本方差。
16.4.1. 样本均值#
样本均值 \(\bar{x}\) 是最简单的统计量。首先考察其期望和方差。我们可以证明
其次,我们考虑 \(\bar{x}\) 的分布。
精确分布:如果 \(x_{1}, x_{2}, \ldots, x_{n}\) 均来自正态分布 \(N\left(\mu, \sigma^{2}\right)\) ,那么 \(\bar{x}\) 的分布是 \(N(\mu,\sigma^2/n)\) 。
近似分布 1(渐近分布):如果 \(x_{1}, x_{2}, \ldots, x_{n}\) 均来自未知分布 \(\Pi\left(\mu, \sigma^{2}\right)\) ,那么,根据 CTL,
近似分布 2(蒙特卡洛分布):如果 \(x_{1},x_{2},\cdots,x_{5}\) 来自于指数分布 \(Exp(1/5)\) ,那么 \(\bar{x} = \frac{1}{5}\sum_{i=1}^5x_i\) 的蒙特卡洛分布应如图 Fig. 16.1 所示。图中直方图刻画的是 \(\bar{x}\) 的蒙特卡洛分布,而红线表示的是其真实的密度函数。
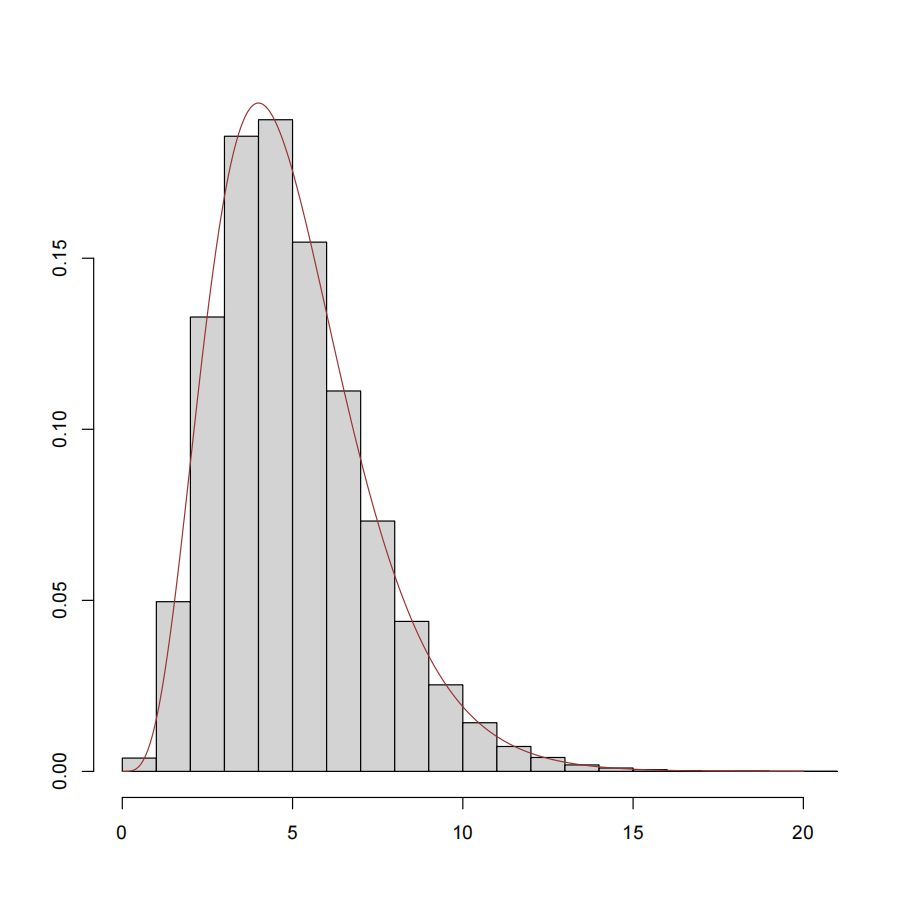
Fig. 16.1 蒙特卡洛分布#
在实现蒙特卡洛分布时,只需要进行以下三步:
从指数分布 \(Exp(1/5)\) 产生 \(5\) 个随机数: \(x_1^{m},x_2^{m},,\cdots,x_5^{m}\) ;
计算 \(\bar{x}^{m} = \frac{1}{5}\sum_{i=1}^5x_i^{m};\)
重复前面两步 \(M\) 次。
由此可以得到 \(M\) 个样本均值的取值,来得到其经验分布函数。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy import stats
import matplotlib.gridspec as gridspec
plt.rcParams["axes.unicode_minus"] = False
sample_sizes = np.array(input("请输入样本量集合(以逗号分隔的正整数 eg: 3, 4, 5, 6, 7, 8, 9, 10, ..., 20):").split(","), dtype=int)
p_values = np.array(input("请输入分位数集合(以逗号分隔的小数 eg: 0.001, 0.01, 0.025, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95, 0.975, 0.99, 0.999):").split(","), dtype=float)
num_simulations = int(input("请输入蒙特卡洛模拟次数(一个正整数 eg: 1500):"))
bins_num = int(input("请输入柱状图间隔数(一个正整数 eg: 50):"))
mean_results = np.zeros((len(p_values), len(sample_sizes)))
variance_results = np.zeros((len(p_values), len(sample_sizes)))
skewness_results = np.zeros((len(p_values), len(sample_sizes)))
kurtosis_results = np.zeros((len(p_values), len(sample_sizes)))
# 对每个样本量进行蒙特卡洛模拟
for i, n in enumerate(sample_sizes):
means = np.zeros(num_simulations)
variances = np.zeros(num_simulations)
skewnesses = np.zeros(num_simulations)
kurtosises = np.zeros(num_simulations)
# 执行蒙特卡洛模拟
for j in range(num_simulations):
sample = np.random.normal(0, 1, n)
means[j] = np.mean(sample)
variances[j] = np.var(sample, ddof=1) # 使用无偏估计
skewnesses[j] = stats.skew(sample)
kurtosises[j] = stats.kurtosis(sample, fisher=True) # Fisher=True表示计算超额峰度
# 计算各统计量的分位数
for k, p in enumerate(p_values):
mean_results[k, i] = np.quantile(means, p)
variance_results[k, i] = np.quantile(variances, p)
skewness_results[k, i] = np.quantile(skewnesses, p)
kurtosis_results[k, i] = np.quantile(kurtosises, p)
fig = plt.figure(figsize=(15, 10))
gs = gridspec.GridSpec(2, 2, figure=fig)
# Plot distribution of sample means
ax1 = fig.add_subplot(gs[0, 0])
ax1.hist(means, bins=bins_num, density=True, alpha=0.7, color='skyblue', label='Sample mean distribution')
x = np.linspace(min(means), max(means), 100)
ax1.plot(x, stats.norm.pdf(x, 0, 1/np.sqrt(n)), 'r-', lw=2, label='Theoretical distribution')
ax1.set_title(f'Monte Carlo distribution of sample means from {n} standard normal samples \n(Simulations: {num_simulations})')
ax1.set_xlabel('Sample mean')
ax1.set_ylabel('Density')
ax1.legend()
ax1.grid(True, linestyle='--', alpha=0.7)
# Plot distribution of sample variances
ax2 = fig.add_subplot(gs[0, 1])
ax2.hist(variances, bins=bins_num, density=True, alpha=0.7, color='lightgreen', label='Sample variance distribution')
df = n - 1
x = np.linspace(min(variances), max(variances), 100)
ax2.plot(x, stats.chi2.pdf((df*x), df) * df, 'r-', lw=2, label='Theoretical distribution')
ax2.set_title(f'Monte Carlo distribution of sample variances from {n} standard normal samples \n(Simulations: {num_simulations})')
ax2.set_xlabel('Sample variance')
ax2.set_ylabel('Density')
ax2.legend()
ax2.grid(True, linestyle='--', alpha=0.7)
# Plot distribution of sample skewness
ax3 = fig.add_subplot(gs[1, 0])
ax3.hist(skewnesses, bins=bins_num, density=True, alpha=0.7, color='salmon', label='Sample skewness distribution')
x = np.linspace(min(skewnesses), max(skewnesses), 100)
ax3.set_title(f'Monte Carlo distribution of sample skewness from {n} standard normal samples \n(Simulations: {num_simulations})')
ax3.set_xlabel('Sample skewness')
ax3.set_ylabel('Density')
ax3.legend()
ax3.grid(True, linestyle='--', alpha=0.7)
# Plot distribution of sample kurtosis
ax4 = fig.add_subplot(gs[1, 1])
ax4.hist(kurtosises, bins=bins_num, density=True, alpha=0.7, color='plum', label='Sample kurtosis distribution')
x = np.linspace(min(kurtosises), max(kurtosises), 100)
ax4.set_title(f'Monte Carlo distribution of sample kurtosis from {n} standard normal samples \n(Simulations: {num_simulations})')
ax4.set_xlabel('Sample kurtosis')
ax4.set_ylabel('Density')
ax4.legend()
ax4.grid(True, linestyle='--', alpha=0.7)
plt.show()
# Create and display quantile tables for the four statistics
def create_quantile_table(results, statistic_name):
df = pd.DataFrame(results, index=p_values, columns=sample_sizes)
df.index.name = 'p'
df.columns.name = 'n'
print(f"\nQuantile table for {statistic_name}:")
print(df)
mean_table = create_quantile_table(mean_results, "sample mean")
variance_table = create_quantile_table(variance_results, "sample variance")
skewness_table = create_quantile_table(skewness_results, "sample skewness")
kurtosis_table = create_quantile_table(kurtosis_results, "sample kurtosis")
Question
如何保留蒙特卡洛分布的信息?
Question
请问 \(\bar{x}\) 的真实分布是什么?
16.4.2. 样本方差和样本标准差#
样本方差 \(s_{n}^2\) 也是一种常用的统计量。为了考虑 \(s_{n}^2\) 的期望,我们可以计算偏差平方和 \(\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}\) 的期望,即
因此,我们发现 \(E(s_n^2) = (n-1)\sigma^2/n \neq \sigma^2\) 。在实际中,我们常采用
作为样本方差。而定义样本标准差为 \(s = \sqrt{s^2}\) 。
16.4.3. 样本偏度和样本峰度(选修)#
- 样本偏度和样本峰度
设 \(x_1,x_2,\cdots,x_n\) 是样本,则称统计量
为样本偏度; 称统计量
为样本峰度。